基础
服务器端处理一次网络请求流程
- 获取请求的数据
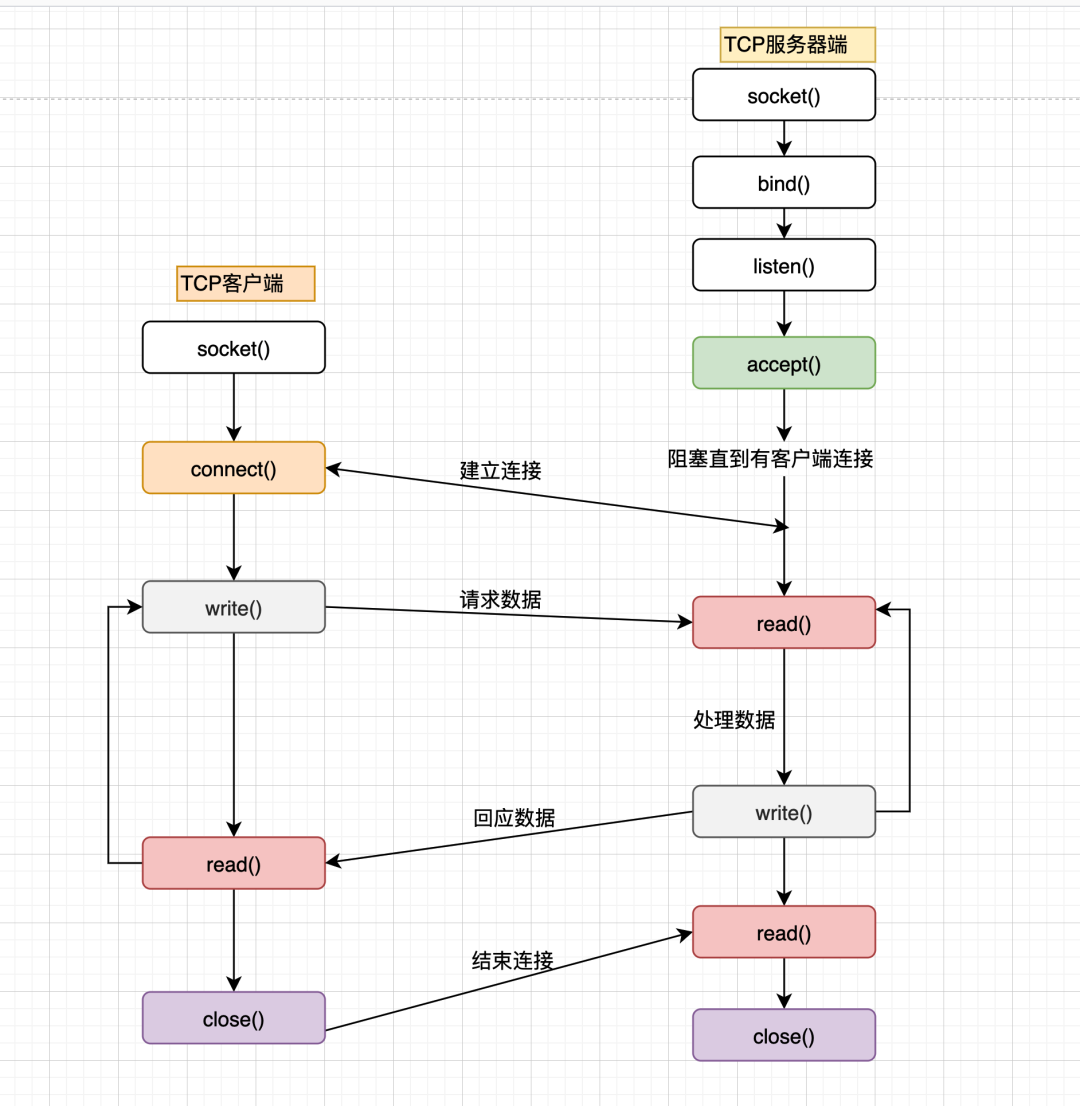
- 客户端与服务器建立连接发出请求,服务器接受请求
- 构建响应数据
- 当服务器接收完请求,并在用户空间处理客户端的请求,直到构建响应完成
- 返回数据
- 服务器将已构建好的响应再通过内核空间的网络 I/O 发还给客户端
内核缓冲区和用户进程缓冲区
说明
在 Linux 系统中,所有的系统资源管理都是在内核空间中完成的。比如读写磁盘文件、分配回收内存、从网络接口读写数据等等。应用程序是无法直接进行这样的操作的。但是可以通过内核提供的接口来完成这样的任务。
比如应用程序要读取磁盘上的一个文件,它可以向内核发起一个 “系统调用” 告诉内核:”我要读取磁盘上的某某文件”。其实就是通过一个特殊的指令让进程从用户态进入到内核态,在内核空间中,CPU 可以执行任何的指令,当然也包括从磁盘上读取数据。具体过程是先把数据读取到内核空间中,然后再把数据拷贝到用户空间并从内核态切换到用户态。此时应用程序已经从系统调用中返回并且拿到了想要的数据,然后往下继续执行
用户进程的IO读写会用到底层的read、write两大系统调用
- read系统调用并不是直接从物理设备把数据读取到应用内存中,而是把数据从内核缓冲区复制到用户进程缓冲区。write也是类似。
- 使用缓冲区的好处就是等待缓冲区达到一定数量的时候,进行IO设备的中断处理,集中执行物理设备实际的IO操作
Linux系统中,操作系统内核只有一个内核缓冲区,每个用户进程都有自己的独立缓冲区。
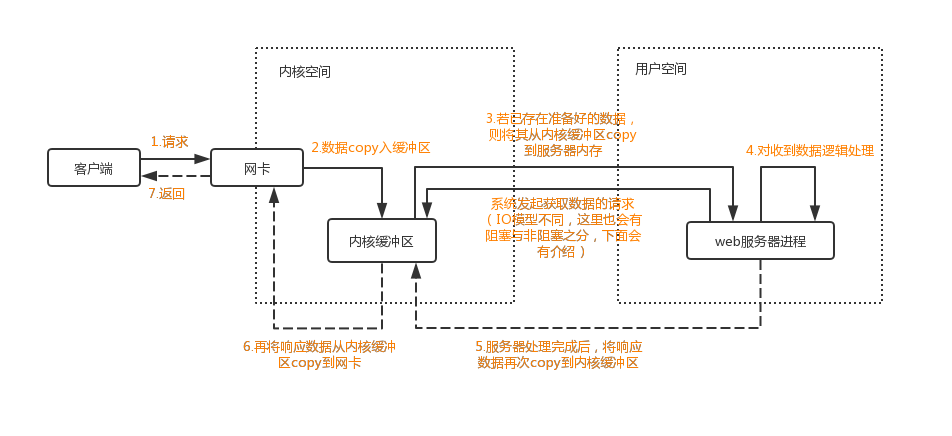
再以上图为例,Java客户端和服务端完成一次socket请求和相应的数据交换流程
- 客户端发送请求:
- Java客户端通过write系统调用将数据复制到内核缓冲区,Linux将内核缓冲区的请求数据通过客户端机器的网卡发送出去。
- 在服务端请求数据会从接收网卡中的数据读取到服务端机器的内核缓冲区
- 服务端获取请求:
- Java服务端通过read系统调用将内核缓冲区的数据读取到用户进程缓冲区进行处理
- 服务器端处理请求
- 具体的业务逻辑
- 服务器端返回数据
- 服务器端处理完请求,通过write系统调用将用户进程数据写入内核缓冲区
- 发送给客户端
- Linux将内核缓冲区的数据写入到网卡,网卡通过底层的通信协议将数据发送给目标客户端
- 客户端发送请求:
文件描述符
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
IO模型
同步阻塞IO(BIO)
说明
阻塞IO和非阻塞IO
- 阻塞IO是指需要内核IO操作彻底完成之后才返回到用户空间执行用户程序;
- 非阻塞IO是指用户空间的程序不需要等待内核IO操作彻底完成,可以立即返回用户空间去执行后续的指令。
同步IO和异步IO
- 同步IO是指用户程序是主动发起IO请求的一方,系统内核是被动接收的一方;
- 异步IO是指系统内核是主动发起IO请求的一方,用户程序是被动接收方。
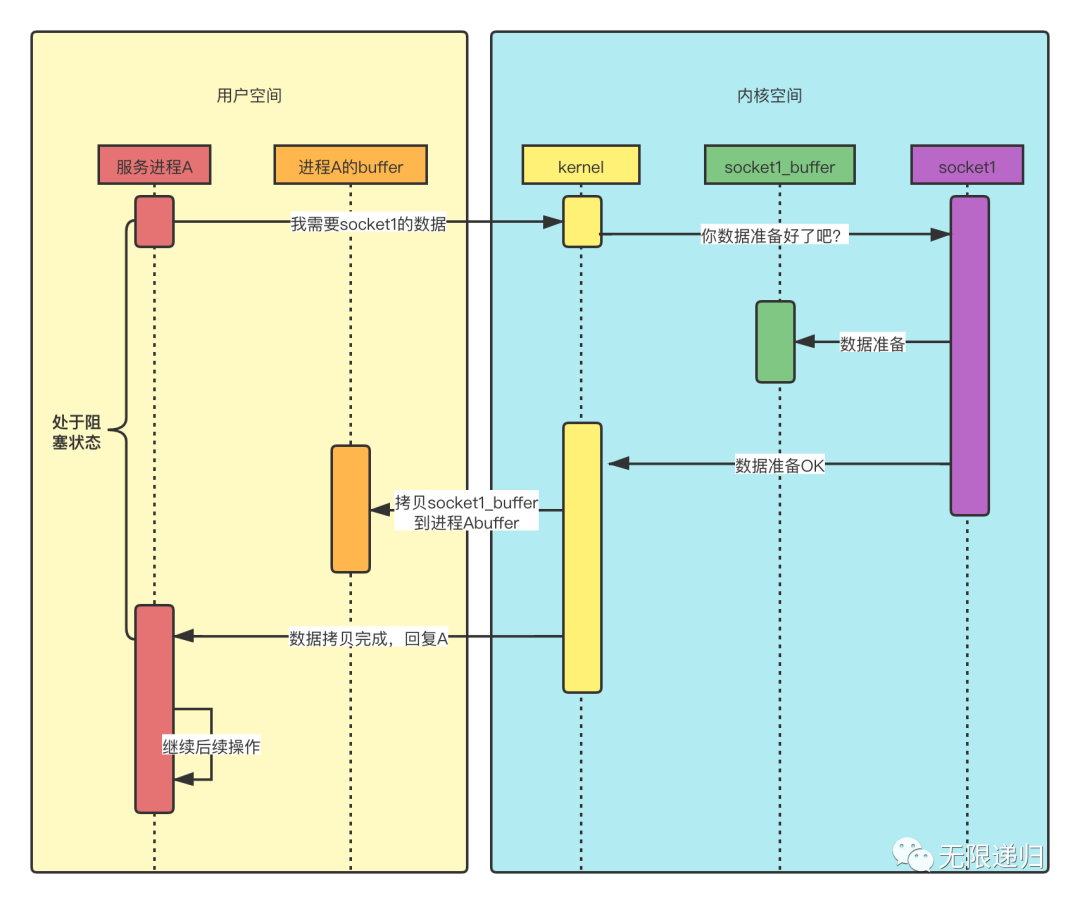
时序图
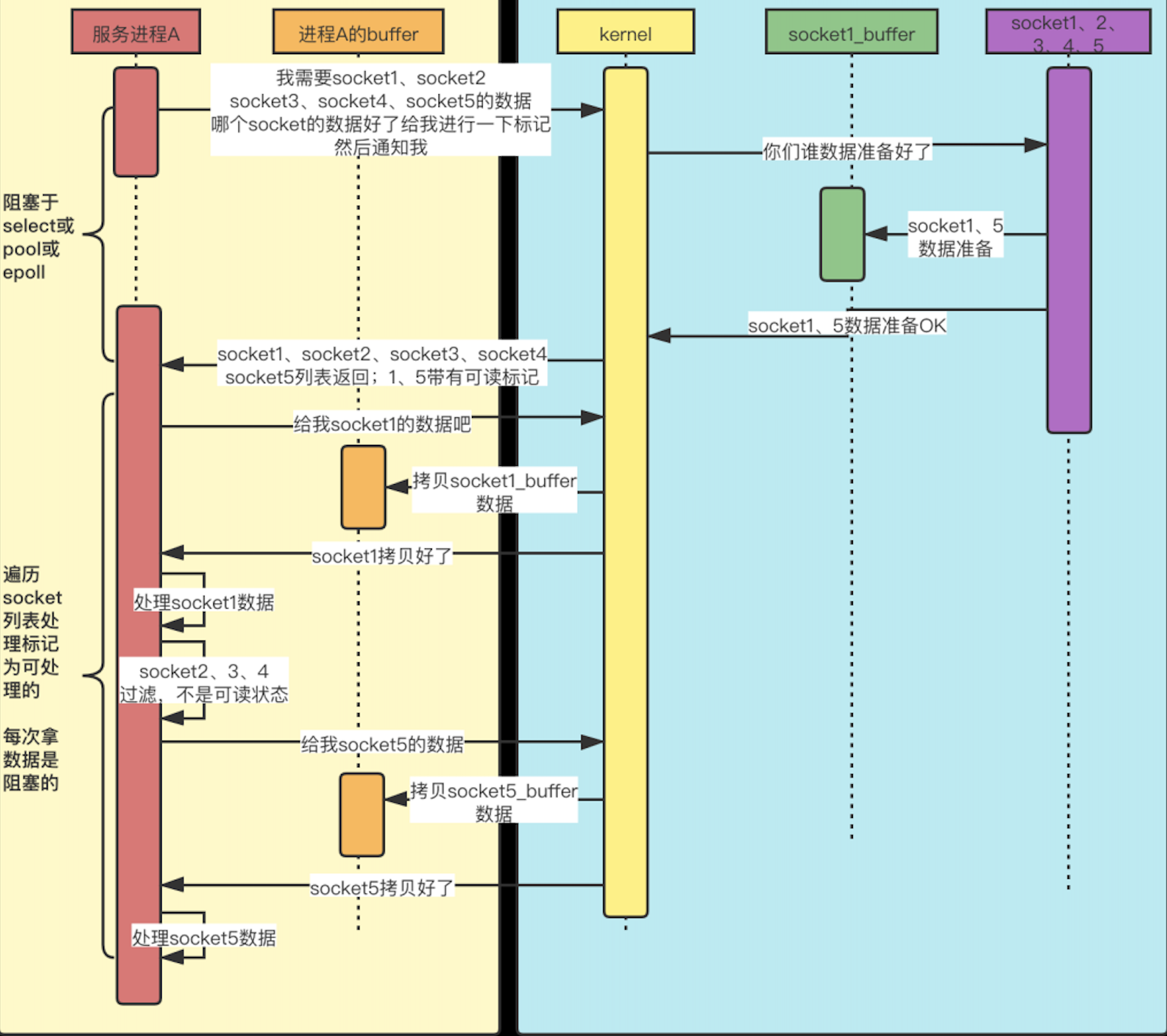
- 用户进程A想要读socket1的数据,这时它发起系统调用,向kernel要数据,但是由于数据还没准备好,所以它发起读取请求后,就阻塞住了,直到数据准备好了,然后kernel把数据从socket1缓冲区拷贝到进程A的缓冲区后,才给进程A做出响应,然后进程A才能继续做后续操作。
BIO代码示例
Java中默认创建的socker都是阻塞IO模型
如下示例
serverSocket.accept()会程序阻塞,并且读取数据时程序也会阻塞,一次只能处理一个请求12345678910111213141516171819202122232425public class SocketServerV1 {public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket(8080);while (true) {System.out.println("等待连接...");// 程序阻塞,等待客户端连接Socket client = serverSocket.accept();System.out.println("有客户端连接服务端...");handle(client);}}private static void handle(Socket client) {try (InputStream inputStream = client.getInputStream();) {byte[] bytes = new byte[1024];// 程序阻塞,没有数据可读时就阻塞int read = inputStream.read(bytes);if (read != -1) {System.out.println("读取客户端数据:" + new String(bytes, StandardCharsets.UTF_8));}} catch (IOException e) {e.printStackTrace();}}}优化一下,可以将处理socket连接的程序放到一个线程中处理(或者线程池)
- 每来一个请求都需要一个线程进行处理,开销大
1234567891011121314151617181920212223242526272829303132public class SocketServerV2 {public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket(8080);while (true) {System.out.println("等待连接...");// 程序阻塞,等待客户端连接final Socket client = serverSocket.accept();System.out.println("有客户端连接服务端...");// 使用线程处理请求new Thread(new Runnable() {public void run() {handle(client);}}).start();}}private static void handle(Socket client) {try (InputStream inputStream = client.getInputStream();) {byte[] bytes = new byte[1024];// 程序阻塞,没有数据可读时就阻塞int read = inputStream.read(bytes);if (read != -1) {System.out.println("读取客户端数据:" + new String(bytes, StandardCharsets.UTF_8));}} catch (IOException e) {e.printStackTrace();}}}调用流程图示
同步非阻塞IO(NIO)
说明
同步非阻塞IO是指用户进程主动发起,不需要等待内核IO操作彻底完成就立即返回用户空间的IO操作,在IO操作过程中,发起IO请求的用户进程或线程处理非阻塞的状态。
非阻塞和阻塞的区别是
- 阻塞是指用户进程或线程一直在等待,不能做别的事情
- 非阻塞是指用户进程或线程获得内核返回的状态值就返回自己的空间,可以去做其他的事情。
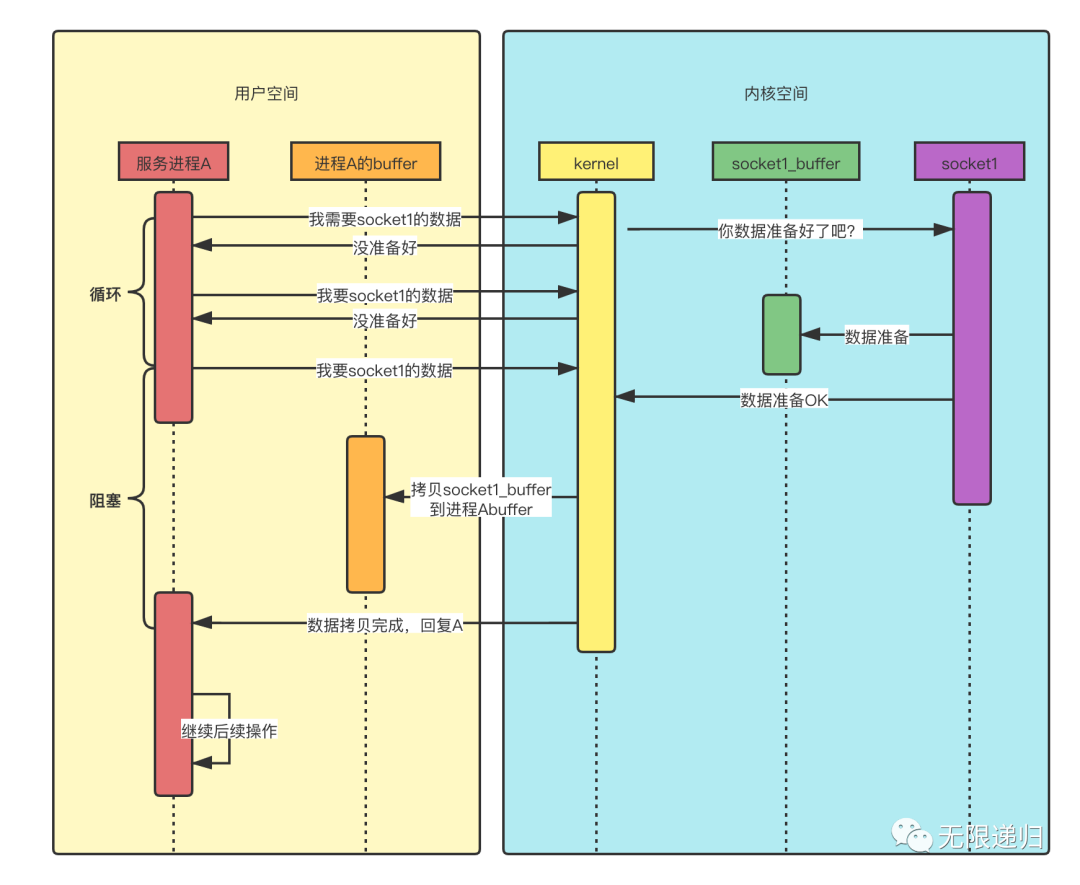
时序图
- 与阻塞IO模型不同的是,当数据未准备好的时候,kernel会先返回给进程A一个消息,告诉它还没准备好,这时进程A就会搞一个while循环,一直在这里不停的问kernel数据好了没(在每次询问之间进程A还是可以做一点其他事情的,而不是像阻塞IO那样啥也不能做,就一直等着),直到数据准备好了,然后开始阻塞住,等待数据拷贝完成,kernel再回复进程A,进程A就可以处理数据了。
- 这里的非阻塞是指发出要数据的请求后,kernel直接会给出一个数据还没准备好的答复,而不像阻塞IO那样,一个回音都没有。但是后面数据准备好了,在数据拷贝的过程中,进程A依然是阻塞的,要等到kernel拷贝好数据后给出答复再进行数据处理。
NIO代码示例
Jdk1.4版本开始支持NIO API
基础的NIO代码如下
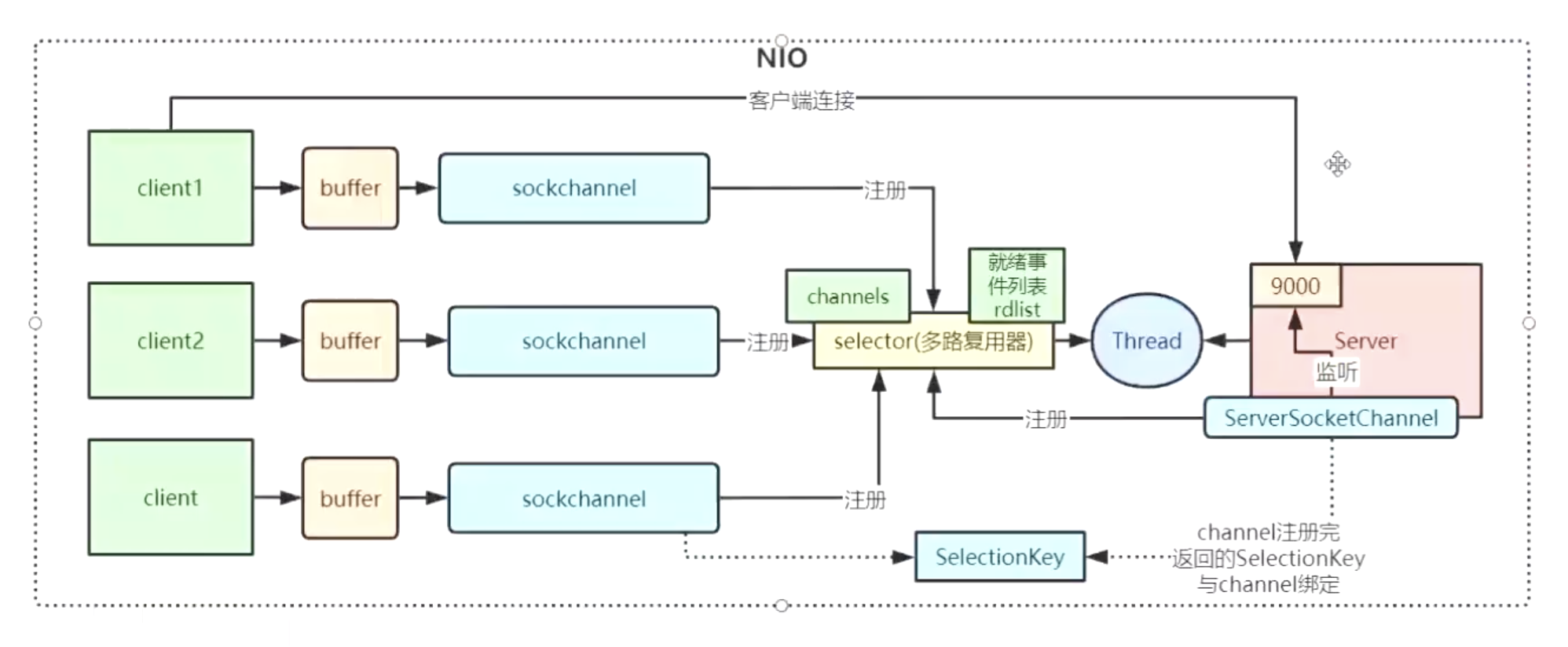
- channelList用于存储socket连接,每次有连接进来就放到集合中,然后遍历集合进行数据的读取
- 遍历channelList会有性能的损耗,下面多路复用就是解决这个问题
123456789101112131415161718192021222324252627282930313233343536public class NioServerV1 {static List<SocketChannel> channelList = new ArrayList<>();public static void main(String[] args) throws IOException {ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.socket().bind(new InetSocketAddress(8080));// 设置ServerSocketChannel为非阻塞serverSocketChannel.configureBlocking(false);System.out.println("服务启动成功");while (true) {// 非阻塞模式accept方法不会阻塞// NIO的非阻塞是由操作系统内部实现的,底层会调用linux内核的accept函数SocketChannel socketChannel = serverSocketChannel.accept();if (socketChannel != null) {System.out.println("客户端连接成功");// 设置SocketChannel为非阻塞socketChannel.configureBlocking(false);channelList.add(socketChannel);}// 遍历连接进行数据的读取Iterator<SocketChannel> iterator = channelList.iterator();while (iterator.hasNext()) {SocketChannel sc = iterator.next();ByteBuffer byteBuffer = ByteBuffer.allocate(256);int read = sc.read(byteBuffer);if (read > 0) {System.out.println("读取客户端数据: " + new String(byteBuffer.array(), StandardCharsets.UTF_8));} else if (read == -1) {iterator.remove();System.out.println("客户端断开连接");}}}}}
IO多路复用
说明
- 为了提高性能,操作系统引入一种新的系统调用,专门用于查询IO文件描述符的就绪状态,通过该系统调用,一个用户进程可以监听多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核就能够将文件描述符的就绪状态返回给用户进程,用户空间可以根据文件描述符的就绪状态进行相应的IO系统调用。
- 通俗理解就是
- 多路是指: 多个业务方(句柄)并发下来的 IO
- 复用是指:复用一个后台处理程序
- 通俗理解就是
时序图
select
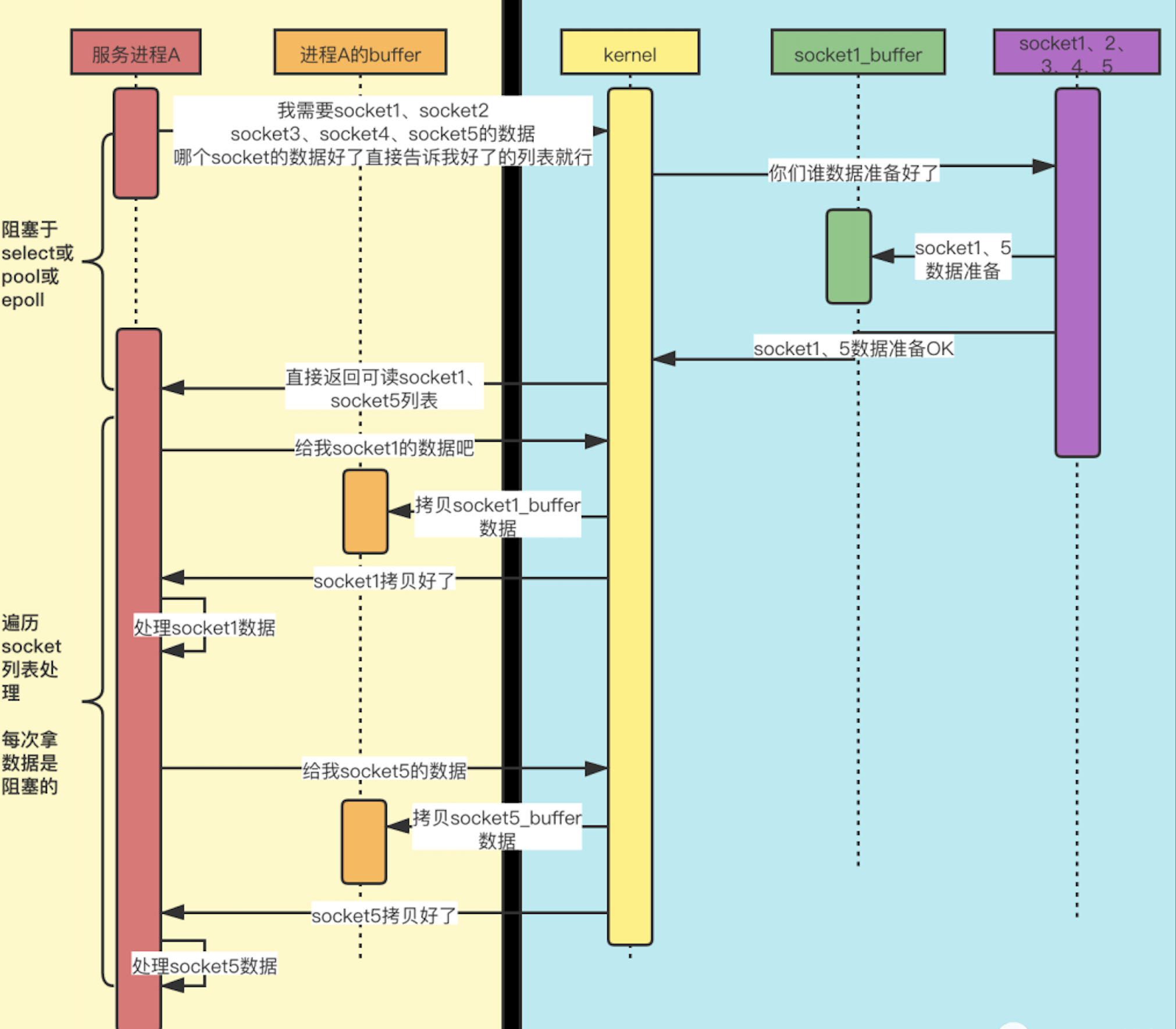
epoll
IO多路复用代码示例
代码流程解析
只处理真正有数据收发的socketchannel
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748public class NioServerV2 {public static void main(String[] args) throws IOException {ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.socket().bind(new InetSocketAddress(8080));// 设置ServerSocketChannel为非阻塞serverSocketChannel.configureBlocking(false);// 打开Selector处理Channel,也就是使用epollSelector selector = Selector.open();// 把ServerSocketChannel注册到Selector上serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);System.out.println("服务启动成功");while (true) {// 阻塞等待需要处理的事件发生selector.select();// 获取selector中注册的全部时间的SelectKey实例Set<SelectionKey> selectionKeys = selector.selectedKeys();Iterator<SelectionKey> iterator = selectionKeys.iterator();while (iterator.hasNext()) {SelectionKey selectionKey = iterator.next();if (selectionKey.isAcceptable()) {// 如果是OP_ACCEPT事件,则进行连接和事件注册ServerSocketChannel server = (ServerSocketChannel) selectionKey.channel();SocketChannel socketChannel = server.accept();socketChannel.configureBlocking(false);// 客户端SocketChannel同样注册到Selector中,服务端监听读事件socketChannel.register(selector, SelectionKey.OP_READ);System.out.println("客户端连接成功");} else if (selectionKey.isReadable()) {// 如果是OP_READ事件,则进行数据读取和打印SocketChannel socketChannel = (SocketChannel) selectionKey.channel();ByteBuffer byteBuffer = ByteBuffer.allocate(256);int len = socketChannel.read(byteBuffer);if (len > 0) {System.out.println("读取客户端数据: " + new String(byteBuffer.array(), StandardCharsets.UTF_8));} else if (len == -1) {// 客户端断开连接,从连接中移除。System.out.println("客户端断开连接");socketChannel.close();}// 从事件集合中删除本次处理的key, 防止限次select重复处理iterator.remove();}}}}}
Selector
select
API
1int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout)- nfds: 最大文件描述符+1
- rset: 读事件集合/位图
- wset: 写事件集合/位图
- eset: 异常事件集合/位图
- time: 等待I/o的最长时间,NULL表示一直等待
代码示例
123456789101112131415161718192021222324252627282930313233// 读事件集合,使用位图表示,默认大小是1024,所以最多处理1024个连接,可修改fd_set rset;int main(int argc, char ** argv){...变量声明、socket端口绑定等省略// 准备5个文件描述符接收客户端的连接for (i=0;i<5;i++) {memset(&client, 0, sizeof (client));addrlen = sizeof(client);fds[i] = accept(sockfd,(struct sockaddr*)&client, &addrlen);if(fds[i] > max){max = fds[i];}}while(1){// rset会被内核修改,每次循环进行需要重新初始化FD_ZERO(&rset);for (i = 0; i< 5; i++ ) {FD_SET(fds[i],&rset);}// select函数,传入读事件集合进行监听处理,如果没有数据到来会阻塞,如果有数据来,会对fd对应的位图置位select(max+1,&rset,NULL,NULL,NULL);// 遍历所有的fd,判断哪个fd被置位了,表示有数据到来,进行数据读取for(i=0;i<5;i++){if(FD_ISSET(fds[i],&rset)){memset(buffer,0,MAXBUF);read(fds[i], buffer, MAXBUF);puts(buffer);}}}return 0;}缺点:
- fd_set默认是1024个;
- fd_set rset不可重用,每次循环需要重新初始化;
- fd_set会从用户态copy到内核态,由内核判断fd是否有数据,虽然是整体的拷贝,但还是存在用户态到内核态的切换;
- 数据到来后,fd_set rset需要再次遍历一遍来判断哪个fd有数据,需要O(n)的复杂度
poll
API
1int poll(struct pollfd *fds, nfds_t nfds, int timeout);- fds: pollfd接口体集合
- nfds: 监听多少个文件描述符
- timeout:超时时间
pollfd结构体:
12345struct pollfd {int fd; /* file descriptor */short events; /* requested events */short revents; /* returned events */};代码示例
- poll和select类似,只是没有采用位图,而是声明了一个结构体pollfd
12345678910111213141516171819202122232425262728int main(int argc, char ** argv){...变量声明、socket端口绑定等省略struct pollfd pollfds[5];for (i=0;i<5;i++){memset(&client, 0, sizeof (client));addrlen = sizeof(client);// 文件描述符为连接的文件pollfds[i].fd = accept(sockfd,(struct sockaddr*)&client, &addrlen);// 接收读事件pollfds[i].events = POLLIN;}sleep(1);while(1){// poll函数,当有数据到来时,会将对应fd的revents置位POLLINpoll(pollfds, 5, 50000);for(i=0;i<5;i++) {if (pollfds[i].revents & POLLIN){// 恢复到之前的状态,然后读取数据pollfds[i].revents = 0;memset(buffer,0,MAXBUF);read(pollfds[i].fd, buffer, MAXBUF);puts(buffer);}}}return 0;}poll解决了select的1、2两个缺点,后面两个缺点还是存在,
epoll
epoll API主要提供三个系统调用
int epoll_create(int size);
创建一个 epoll 对象
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
Linux 内核会创建一个 eventpoll 结构体,这个结构体中有两个成员与epoll的使用方式密切相关:
- wq: 等待队列链表。软中断数据就绪的时候会通过 wq 来找到阻塞在 epoll 对象上的用户进程。
- rbr: 一棵红黑树。为了支持对海量连接的高效查找、插入和删除,eventpoll 内部使用了一棵红黑树。通过这棵树来管理用户进程下添加进来的所有 socket 连接。
- rdllist: 就绪的描述符的链表。当有的连接就绪的时候,内核会把就绪的连接放到 rdllist 链表里。这样应用进程只需要判断链表就能找出就绪进程,而不用去遍历整棵树。
123456789101112struct eventpoll {.../*等待队列链表*/wait_queue_head_t wq;/*红黑树的根节点,这棵树中存储着所有添加到epoll中的事件,也就是这个epoll监控的事件*/struct rb_root rbr;/*双向链表rdllist保存着将要通过epoll_wait返回给用户的、满足条件的事件*/struct list_head rdllist;...};
- 我们在调用 epoll_create 时,内核除了帮我们在 epoll 文件系统里建了个 file 结点,在内核 cache 里建了个红黑树用于存储以后 epoll_ctl 传来的 socket 外,还会再建立一个 rdllist 双向链表,用于存储准备就绪的事件,当 epoll_wait 调用时,仅仅观察这个 rdllist 双向链表里有没有数据即可。有数据就返回,没有数据就 sleep,等到 timeout 时间到后即使链表没数据也返回。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
向 epoll 对象中添加要管理的连接epfd:是epoll_create()的返回值。
op:表示op操作,用三个宏来表示:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD。分别添加、删除和修改对fd的监听事件。
fd:是需要监听的fd(文件描述符)
epoll_event:是告诉内核需要监听什么事,struct epoll_event结构如下:
1234struct epoll_event {__uint32_t events; /* Epoll events */epoll_data_t data; /* User data variable */};//events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里如果增加 socket 句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据;
- 软中断:是执行中断指令产生的,无外部施加中断请求信号,因此中断的发生不是随机的而是程序安排好的,比如编程异常(1/0),系统调用就是典型的软中断。
- 硬中断:是由与系统相连的外部设备产生的,比如磁盘、网卡、键盘、鼠标、时钟等,因此具有随机性和突发性,每个设备都有它自己的IRQ(中断请求)。基于IRQ,CPU可以将相应的请求分发到对应的硬件驱动(中断处理程序)上。
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待其管理的连接上的 IO 事件,就是负责打盹的,让出 CPU 调度,但是只要有“事”,立马会从这里唤醒;
- 等待epfd上的io事件,最多返回maxevents个事件。
- 参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,
- 参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。
- 该函数返回需要处理的事件数目,如返回0表示已超时。
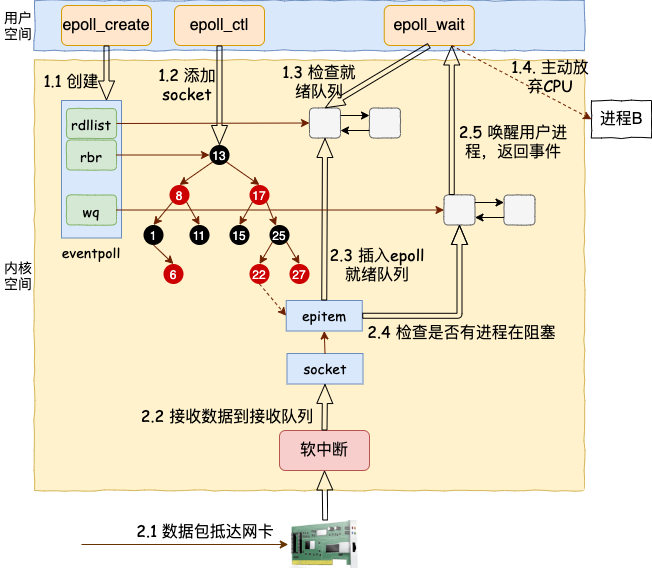
调用图示
epoll的两种触发模式
LT(水平触发)模式下,只要这个文件描述符还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作;
ET(边缘触发)模式下,在它检测到有 I/O 事件时,通过 epoll_wait 调用会得到有事件通知的文件描述符,对于每一个被通知的文件描述符,如可读,则必须将该文件描述符一直读到空,让 errno 返回 EAGAIN 为止,否则下次的 epoll_wait 不会返回余下的数据,会丢掉事件。
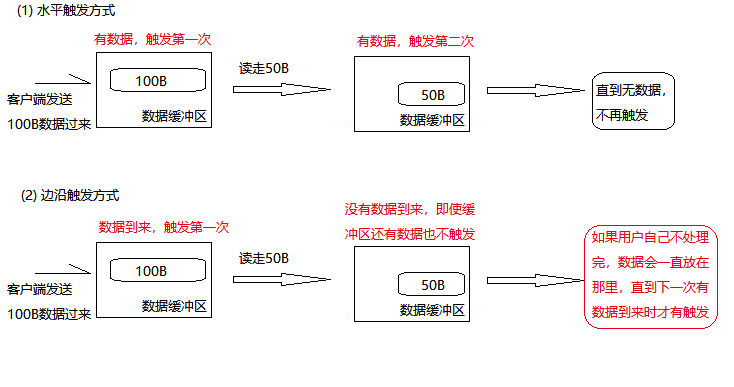
- 如果采用 EPOLLLT 模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边缘触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
代码示例
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647int main(int argc, char ** argv) {...变量声明、socket端口绑定等省略int epfd, epct, i;// 定义epoll事件struct epoll_event event;// 定义epoll事件集合struct epoll_event events[20];memset(events, 0, 20 * sizeof(struct epoll_event));// 创建epoll的fd,红黑树epfd = epoll_create(1);event.data.fd = serverFd;// 填充事件类型,监听读事件event.events = EPOLLIN;// 把serverFd(监听FD)和事件添加到红黑树上epoll_ctl(epfd, EPOLL_CTL_ADD, serverFd, &event);while(1) {// 等待时间到来,阻塞模式,同时监听20个事件,返回就绪的事件个数epct = epoll_wait(epfd, events, 20, -1);// 根据epoll返回的值查询事件for (i = 0; i < epct; i++) {if (events[i].data.fd == serverFd) {socklen_t length = sizeof(clientAddr);clientFd = accept(events[i].data.fd, (struct sockaddr *)&clientAddr, &length);printf("new fd=%d ip %s\n", clientFd, inet_ntoa(clientAddr.sin_addr));event.data.fd = clientFd;event.events = EPOLLIN | EPOLLET;// event.events = EPOLLIN;epoll_ctl(epfd, EPOLL_CTL_ADD, clientFd, &event);} else {printf("new data arrive\n");// 如果不是serverFd, 就是clientFd的读事件memset(buf, 0, BUFLEN);rlen = read(events[i].data.fd, buf, BUFLEN);if (rlen <= 0) {// 客户端断开printf("fd %d disconnected\n", events[i].data.fd);close(events[i].data.fd);epoll_ctl(epfd, EPOLL_CTL_DEL, events[i].data.fd, &event);continue;}printf("fd: %d data: %s\n", events[i].data.fd, buf);}}}}
解决了select和poll的缺点
三种对比
| select | poll | epoll | |
|---|---|---|---|
| 底层数据结构 | 数组存储文件描述符 | 链表存储文件描述符 | 红黑树存储监控的文件描述符,双链表存储就绪的文件描述符 |
| 如何从fd数据中获取就绪的fd | 遍历fd_set | 遍历链表 | 回调 |
| 时间复杂度 | 获得就绪的文件描述符需要遍历fd数组,O(n) | 获得就绪的文件描述符需要遍历fd链表,O(n) | 当有就绪事件时,系统注册的回调函数就会被调用,将就绪的fd放入到就绪链表中。O(1) |
| FD数据拷贝 | 每次调用select,需要将fd数据从用户空间拷贝到内核空间 | 每次调用poll,需要将fd数据从用户空间拷贝到内核空间 | 使用内存映射(mmap),不需要从用户空间频繁拷贝fd数据到内核空间 |
| 最大连接数 | 有限制,一般为1024 | 无限制 | 无限制 |
Reactor设计模式
wikipedia的描述
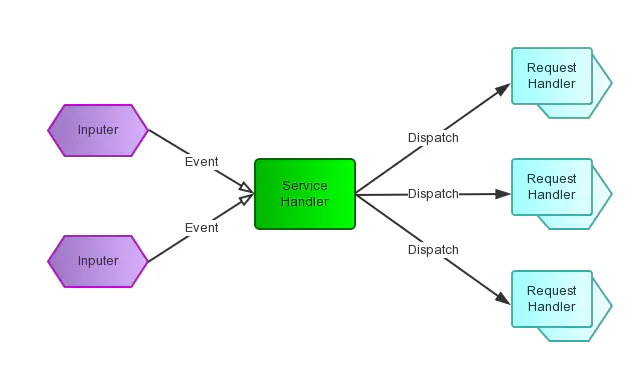
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to associated request handlers.
Reactor模式是处理并发I/O常见的一种模式,用于同步I/O,其中心思想是将所有要处理的I/O事件注册到一个中心I/O多路复用器上,同时主线程阻塞在多路复用器上,一旦有I/O事件到来或是准备就绪,多路复用器将返回并将相应
I/O事件分发到对应的处理器中。- Reactor是一种事件驱动机制,和普通函数调用不同的是应用程序不是主动的调用某个API来完成处理,恰恰相反的是Reactor逆置了事件处理流程,应用程序需提供相应的接口并注册到Reactor上,如果有相应的事件发生,Reactor将主动调用应用程序注册的接口(回调函数)
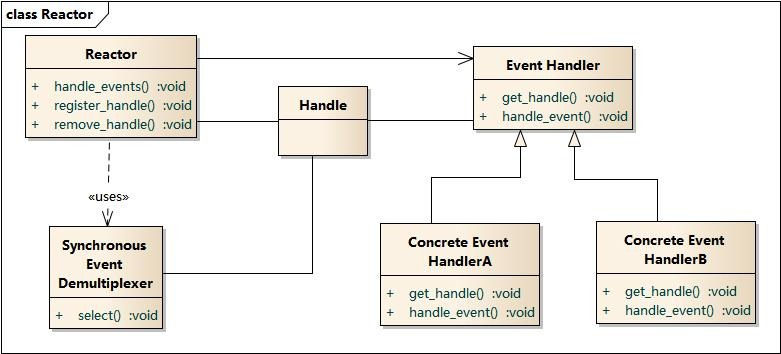
Reactor模式结构
- Handle 句柄;用来标识socket连接或是打开文件;
- Synchronous Event Demultiplexer:同步事件多路分解器:由操作系统内核实现的一个函数;用于阻塞等待发生在句柄集合上的一个或多个事件;(如select/epoll;)
- Event Handler:事件处理接口
- Concrete Event HandlerA:实现应用程序所提供的特定事件处理逻辑;
- Reactor:反应器,定义一个接口,实现以下功能: 1)供应用程序注册和删除关注的事件句柄; 2)运行事件循环; 3)有就绪事件到来时,分发事件到之前注册的回调函数上处理;
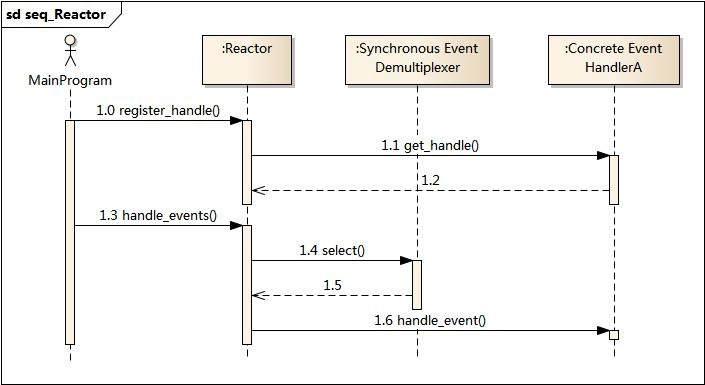
Reactor时序图
应用启动,将关注的事件handle注册到Reactor中;
调用Reactor,进入无限事件循环,等待注册的事件到来;
事件到来,select返回,Reactor将事件分发到之前注册的回调函数中处理;
单线程
单线程的
Reactor模式对于客户端的所有请求使用一个专门的线程去处理,这个线程无限循环地监听是否有客户端的请求抵达,一旦收到客户端的请求,就将其分发给响应处理程序进行处理。Reactor负责响应IO事件,当检测到一个新的事件会将其发送给相应的处理程序去处理。Handler负责处理非阻塞的行为,标识系统管理的资源,同时将处理程序与事件绑定。
单线程的Reactor与NIO流程类似,只是将消息相关处理独立到
Handler中。虽然NIO中一个线程可以支持所有的IO处理,但瓶颈也是显而易见的。如果某个客户端多次进行请求时在Handler中的处理速度较慢,那么后续的客户端请求都会被积压,导致响应变慢。所以需要引入Reactor多线程模型。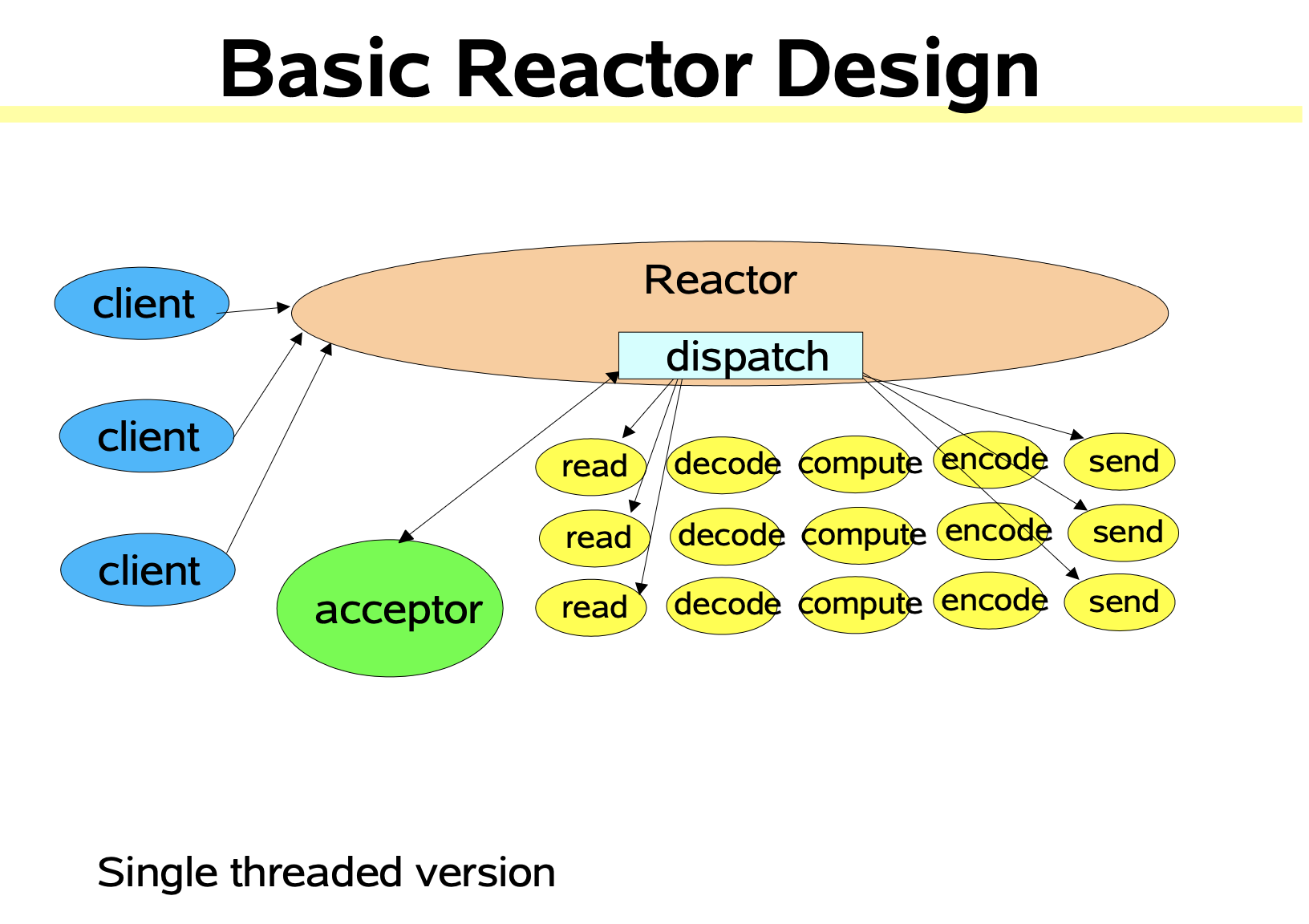
多线程
- 考虑到工作线程的复用,可以将工作线程设计线程池。将处理器的执行放入线程池,并使用多线程处理业务逻辑,Reactor仍然是单个线程。
- Reactor读线程模型是将Handler中的IO操作和非IO操作分开,操作IO的线程称为IO线程,非IO操作的线程称为工作线程。客户端的请求会被直接丢到线程池中,因此不会发生堵塞。
- 多线程的Reactor的特点是一个Reactor线程和多个处理线程,将业务处理即
process交给线程池进行了分离,Reactor线程只关注事件分发和字节的发送和读取。需要注意的是,实际的发送和读取还是由Reactor来处理。当在高并发环境下,有可能会出现连接来不及接收。- 当用户进一步增加时Reactor也会出现瓶颈,因为Reactor既要处理IO操作请求也要响应连接请求。为了分担Reactor的负担,可以引入主从Reactor模型。
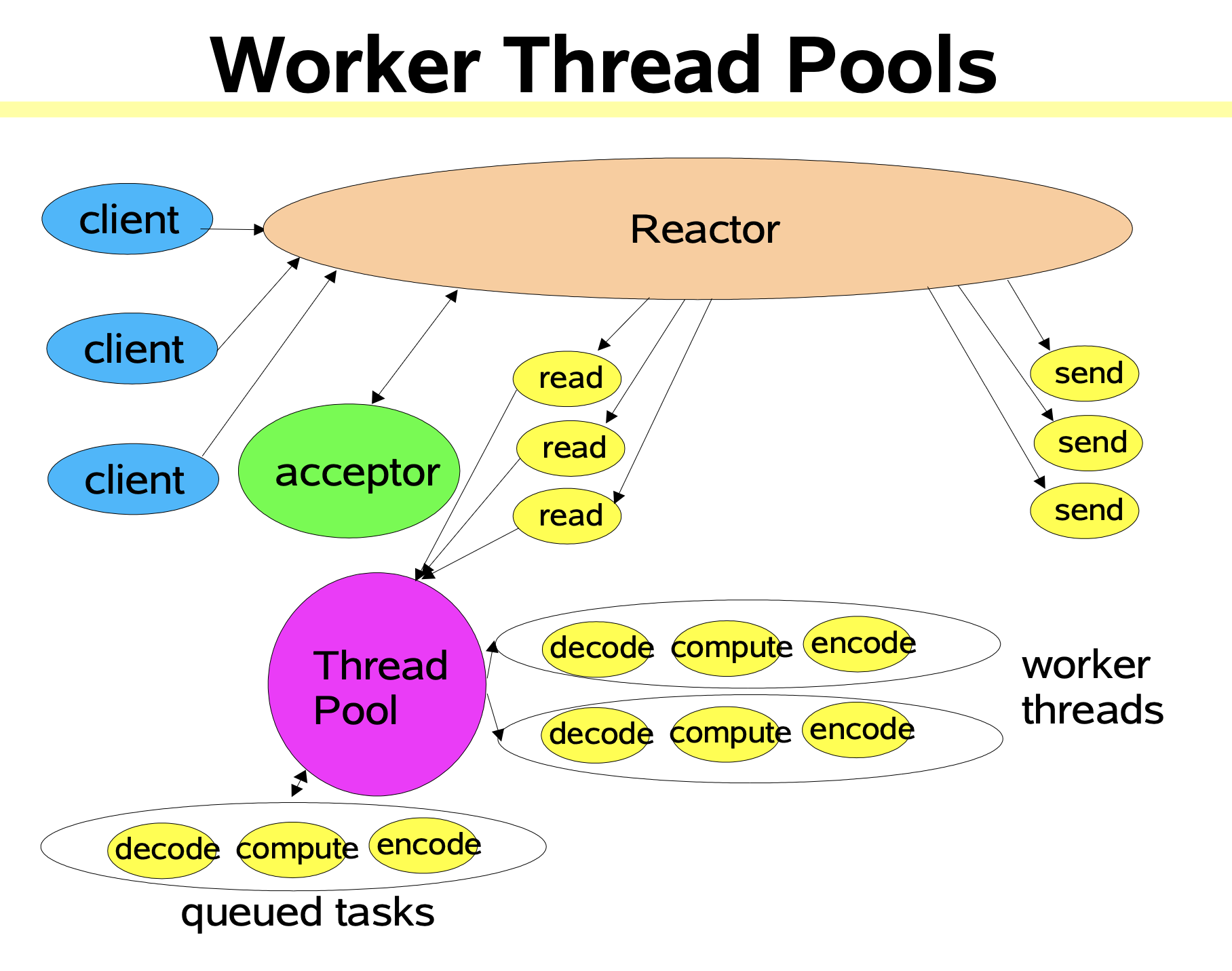
主从多线程
- 对于多个CPU的机器,为了充分利用系统资源会将Reactor拆分为两部分。
- Main Reactor 负责监听连接,将
accept连接交给Sub Reactor处理,主Reactor用于响应连接请求。 - Sub Reactor 处理
accept连接,从Reactor用于处理IO操作请求。
- Main Reactor 负责监听连接,将
- 主从Reactor的特点是使用 一个
Selector池,通常有一个主Reactor用于处理接收连接事件,多个从Reactor处理实际的IO。整体来看,分工合作,分而治之,非常高效。 - 为什么需要单独拆分一个Reactor来处理监听呢?
- 因为像TCP这样需要经过3次握手才能建立连接,这个建立的过程也是需要消耗时间和资源的,单独拆分一个Reactor来处理,可以提高性能。
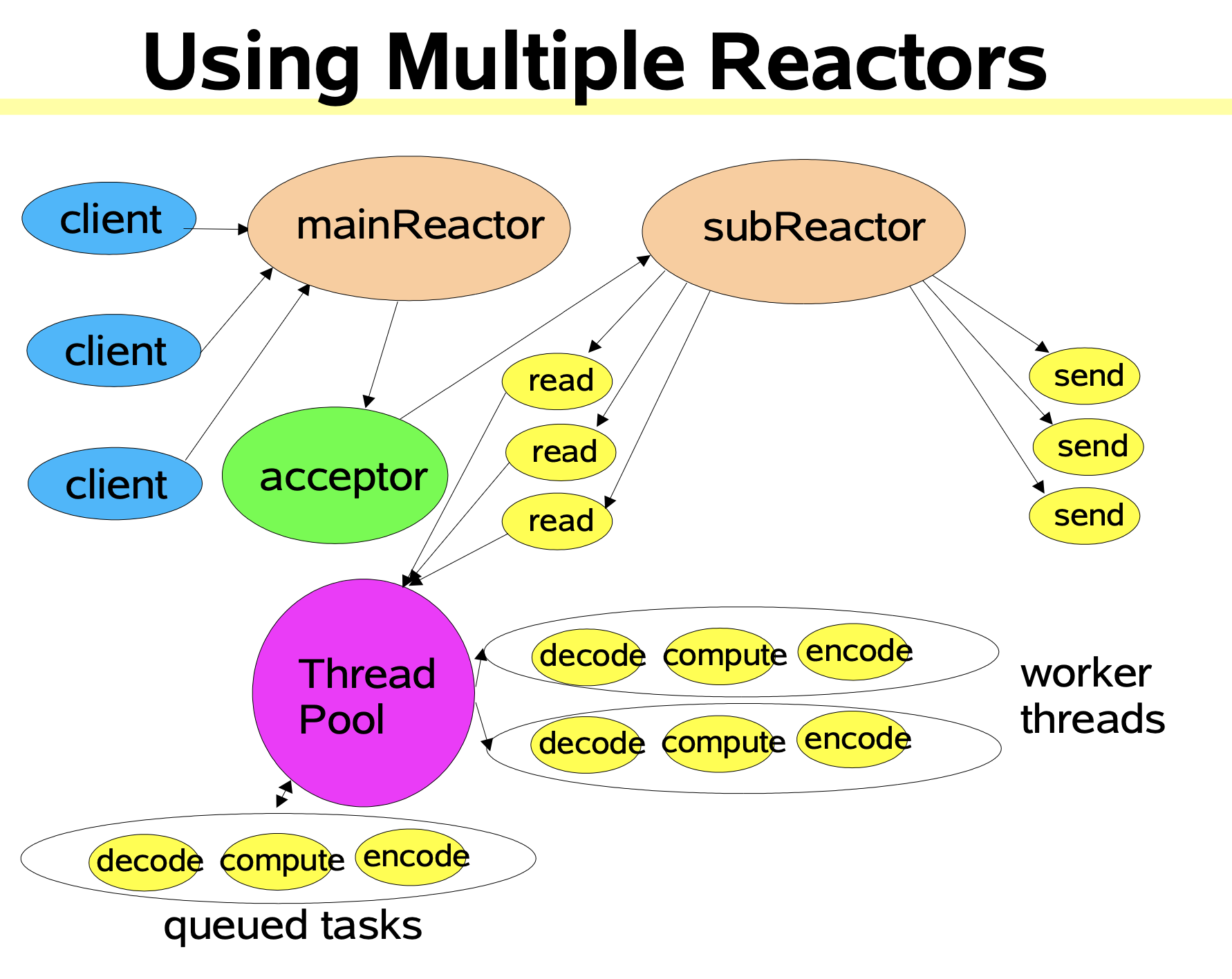
netty模型图
- Netty 抽象出两组线程池:BossGroup 和 WorkerGroup,
- BossGroup 中的线程专门负责和客户端建立连接,
- WorkerGroup中的线程专门负责处理连接上的读写。
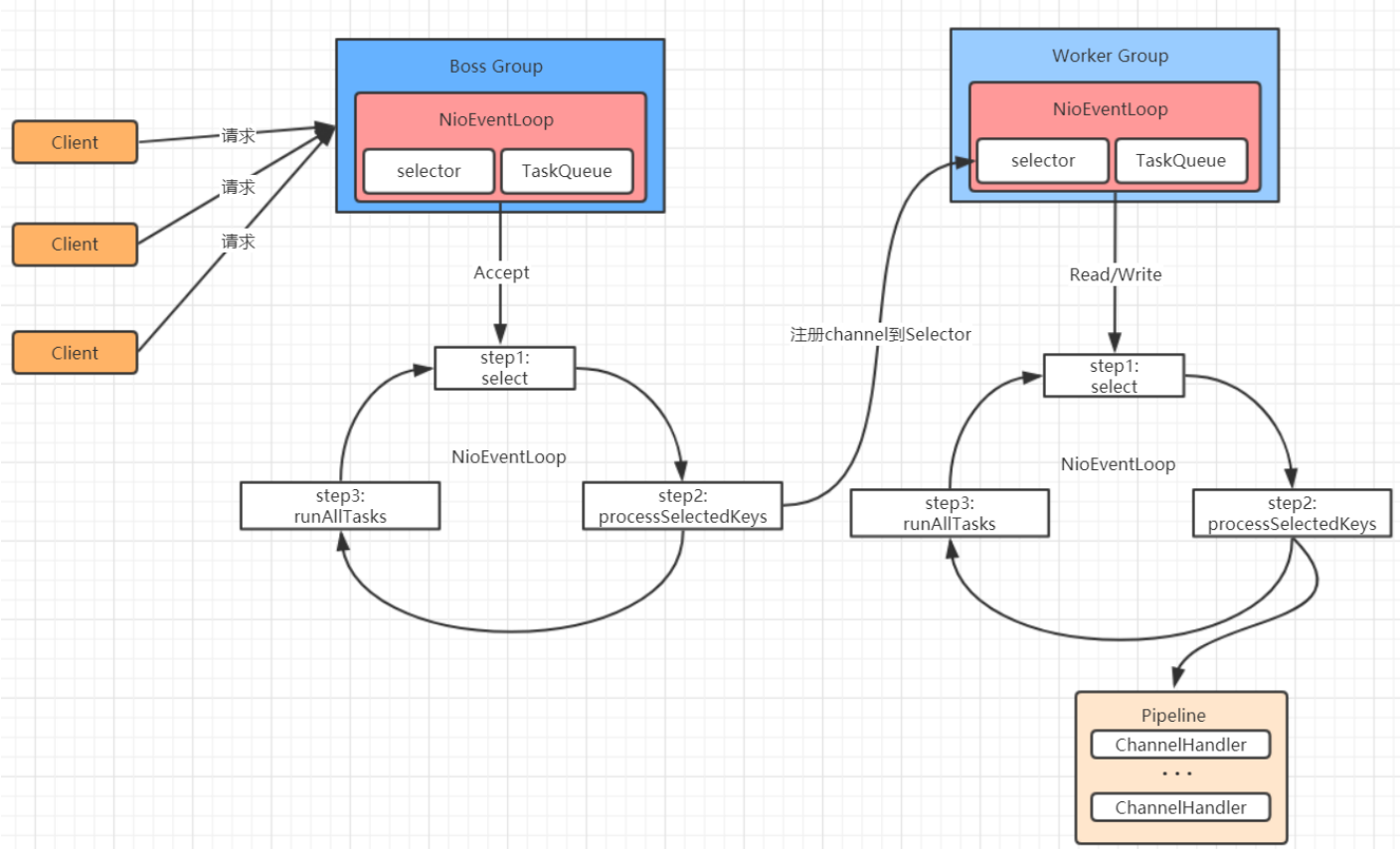
工作流程(Epoll为例)
主线程向
epoll内核事件表中注册socket上的读就绪事件主线程调用
epoll_wait等待socket上有数据可读当
socket上有数据可读时,epoll_wait通知主线程,主线程将socket可读事件放入请求队列。休眠在请求队列上的某个工作线程被唤醒,从
socket中读取数据并处理客户端请求,然后向epoll内核事件表中注册该socket上的写就绪事件。主线程调用
epoll_wait等待socket可写当
socket可写时epoll_wait通知主线程,主线程将socket可写事件放入请求队列。休眠在请求队列上的某个工作线程被唤醒,向
socket上写入服务器处理客户请求的结果。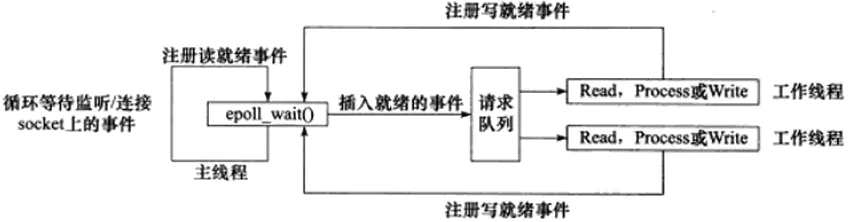
Reactor优缺点
优点
响应快,不为单个同步时间所阻塞,虽然Reactor自身依然是同步的。
编程相对简单,可以最大程度的避免复杂的多线程以及同步问题和多线程以及多进程的切换开销。
可扩展性,可以方便的通过增加Reactor实例个数来充分利用CPU资源。
可复用性, Reactor框架本身与具体事件处理逻辑无关,具有很高的复用性。
缺点
Reactor增加了一定的复杂性,因而具有一定的门槛,并且不易于调试。
Reactor模式需要底层的
Synchronous Event Demultiplexer支持,比如Java中的Selector支持,操作系统的select系统调用支持。Reactor模式在IO读写数据时会在同一线程中实现,即使使用多个Reactor机制的情况下,那些共享一个Reactor的Channel如果出现一个长时间的数据读写,会影响这个Reactor中其他Channel的相应时间。例如在大文件传输时,IO操作会影响其他客户端的时间,因而对于这种操作,使用传统的
Thread-Per-Connection或许是一个更好的选择,或者采用Proactor模式。
单线程Reactor代码示例
Reactor负责响应IO事件,当检测到一个新的事件会将其发送给相应的处理程序去处理
首次连接进来,调用dispatch方法,获取到Acceptor实例处理连接
客户端发送数据,获取到BasicHandler实例进行处理数据
|
|
信号量驱动
说明
在信号驱动式 I/O 模型中,应用程序使用套接口进行信号驱动 I/O,并安装一个信号处理函数,进程继续运行并不阻塞。
当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 I/O 操作函数处理数据。
- 比喻:鱼竿上系了个铃铛,当铃铛响,就知道鱼上钩,然后可以做别的事情。
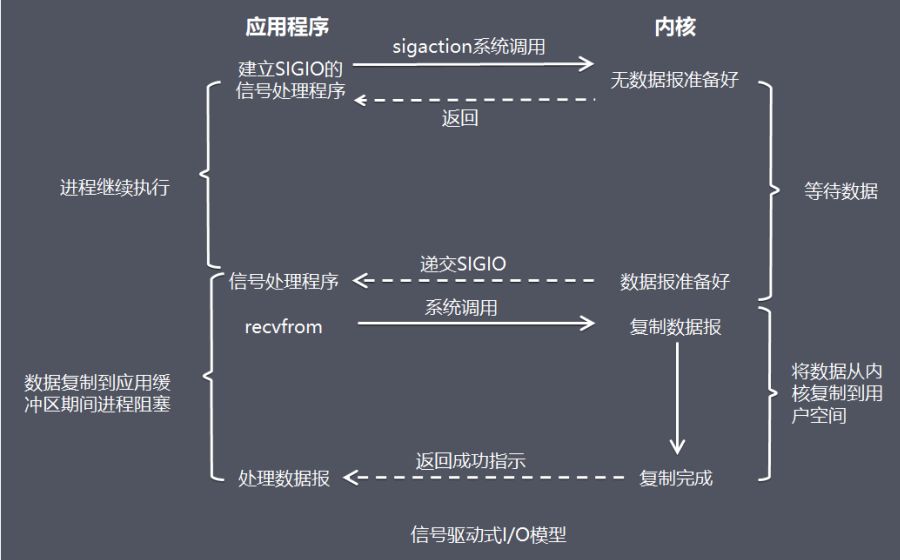
时序图
- 开启套接字信号驱动IO功能
- 系统调用Sigaction执行信号处理函数(非阻塞,立刻返回)
- 数据就绪,生成Sigio信号,通过信号回调通知应用来读取数据
- 此种IO方式存在的一个很大的问题:Linux中信号队列是有限制的,如果超过这个数字问题就无法读取数据
优缺点
- 信号驱动式IO对于TCP套接字产生的作用不大。因为该信号在TCP套接字中产生的过于频繁。以下条件均会导致对一个TCP套接字产生SIGIO信号:
- 监听套接字上某个连接请求已经完成;
- 某个断连请求已经发起;
- 某个断连请求已经完成;
- 某个连接之半已经关闭;
- 数据到达套接字;
- 数据已经从套接字发送走;
- 发生某个异步错误。
- UDP套接字中,只有以下两个条件会产生SIGIO信号:
- 数据报到达套接字;
- 套接字上发生异步错误。
异步IO
说明
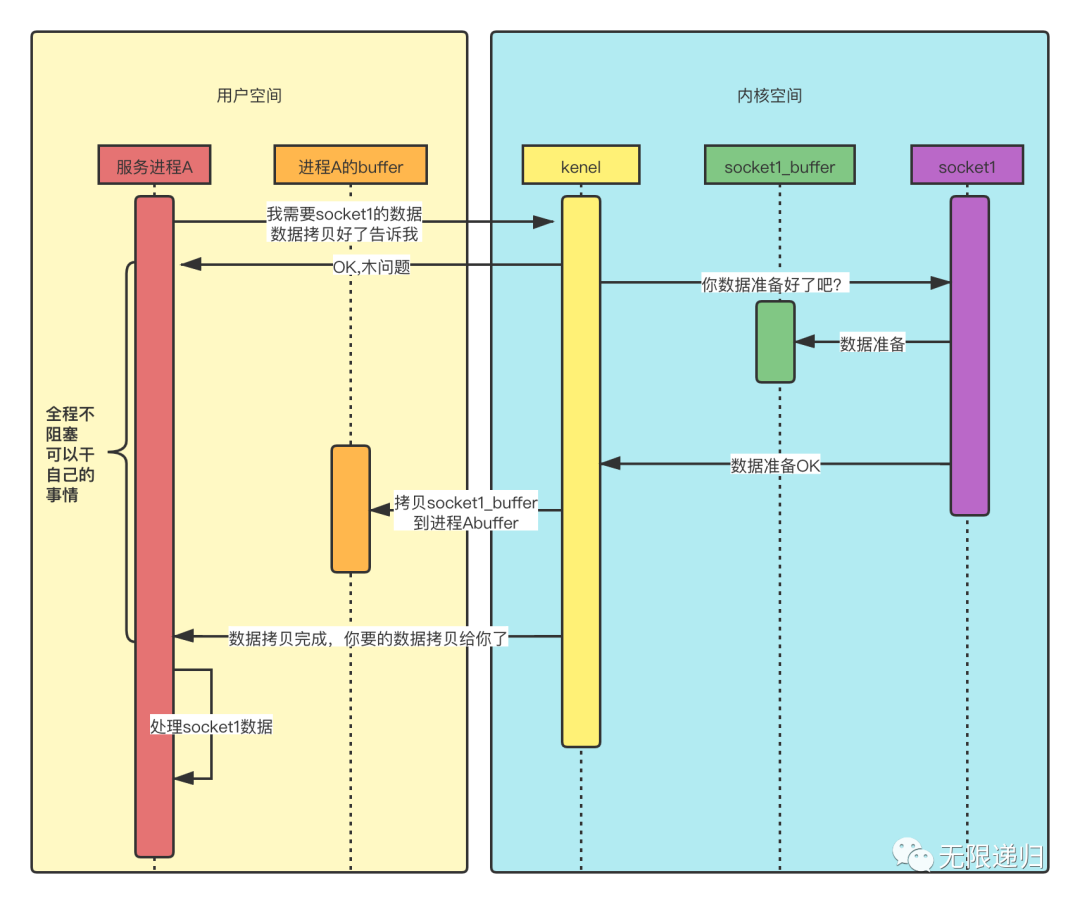
异步IO模型的基本流程是:
- 用户线程通过系统调用向内核注册某个IO操作
内核在整个IO操作(包括数据准备、数据复制)完成后通知用户程序,用户执行后续的业务操作
在整个内核的数据准备过程中,用户程序都不需要阻塞
与NIO不同,当进行读写操作时,只需要直接调用API的read或write方法即可,这两种方法均为异步的,对于读操作而言,当有流可读时,操作系统会将可读的流传入read方法的缓冲区,对于写操作而言,当操作系统将write方法传入的流写入完毕是,操作系统会主动通知应用程序
- read和write方法都是异步的,完成后主动调用回调函数。
时序图
异步IO代码示例
| BIO | NIO | AIO |
|---|---|---|
| Socket | SocketChannel | AsynchronousSocketChannel |
| ServerSocket | ServerSocketChannel | AsynchronousServerSocketChannel |
Server
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849public class AioServer {static int PORT = 8080;static String CHARSET = "utf-8"; //默认编码static CharsetDecoder decoder = Charset.forName(CHARSET).newDecoder(); //解码int port;AsynchronousServerSocketChannel serverChannel;public AioServer(int port) throws IOException {this.port = port;}public void listen() throws Exception {//打开一个服务通道//绑定服务端口this.serverChannel = AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(port), 100);this.serverChannel.accept(this, new AcceptHandler());Thread t = new Thread(() -> {while (true) {System.out.println("运行中...");try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}public static void close(AsynchronousSocketChannel client) {try {client.close();} catch (Exception e) {e.printStackTrace();}}public static void main(String[] args) {try {System.out.println("正在启动服务...");AioServer server = new AioServer(PORT);server.listen();} catch (Exception e) {e.printStackTrace();}}}AcceptHandler
- 接收请求处理,如果有连接请求进来,读取客户端数据
12345678910111213141516171819202122232425262728293031323334public class AcceptHandler implements CompletionHandler<AsynchronousSocketChannel, AioServer> {static int BUFFER_SIZE = 1024;public void completed(final AsynchronousSocketChannel client, AioServer attachment) {try {System.out.println("远程地址:" + client.getRemoteAddress());//tcp各项参数client.setOption(StandardSocketOptions.TCP_NODELAY, true);client.setOption(StandardSocketOptions.SO_SNDBUF, 1024);client.setOption(StandardSocketOptions.SO_RCVBUF, 1024);if (client.isOpen()) {System.out.println("client.isOpen:" + client.getRemoteAddress());final ByteBuffer buffer = ByteBuffer.allocate(BUFFER_SIZE);buffer.clear();client.read(buffer, client, new ReadHandler(buffer));}} catch (Exception e) {e.printStackTrace();} finally {attachment.serverChannel.accept(attachment, this);// 监听新的请求,递归调用。}}public void failed(Throwable exc, AioServer attachment) {try {exc.printStackTrace();} finally {attachment.serverChannel.accept(attachment, this);// 监听新的请求,递归调用。}}}ReadHandler
- 读取客户端数据,处理请求完之后相应客户端
12345678910111213141516171819202122232425262728293031323334353637public class ReadHandler implements CompletionHandler<Integer, AsynchronousSocketChannel> {private ByteBuffer buffer;public ReadHandler(ByteBuffer buffer) {this.buffer = buffer;}public void completed(Integer result, AsynchronousSocketChannel attachment) {try {if (result < 0) {// 客户端关闭了连接AioServer.close(attachment);} else if (result == 0) {System.out.println("空数据"); // 处理空数据} else {// 读取请求,处理客户端发送的数据buffer.flip();CharBuffer charBuffer = AioServer.decoder.decode(buffer);System.out.println(charBuffer.toString()); //接收请求//响应操作,服务器响应结果buffer.clear();String res = "HTTP/1.1 200 OK" + "\r\n\r\n" + "hellworld";buffer = ByteBuffer.wrap(res.getBytes());attachment.write(buffer, attachment, new WriteHandler(buffer));//Response:响应。}} catch (Exception e) {e.printStackTrace();}}public void failed(Throwable exc, AsynchronousSocketChannel attachment) {exc.printStackTrace();AioServer.close(attachment);}}WriteHandler
- 处理完相应,服务端关闭连接
12345678910111213141516171819public class WriteHandler implements CompletionHandler<Integer, AsynchronousSocketChannel>{private ByteBuffer buffer;public WriteHandler(ByteBuffer buffer) {this.buffer = buffer;}public void completed(Integer result, AsynchronousSocketChannel attachment) {buffer.clear();AioServer.close(attachment);}public void failed(Throwable exc, AsynchronousSocketChannel attachment) {exc.printStackTrace();AioServer.close(attachment);}}
Proactor设计模式
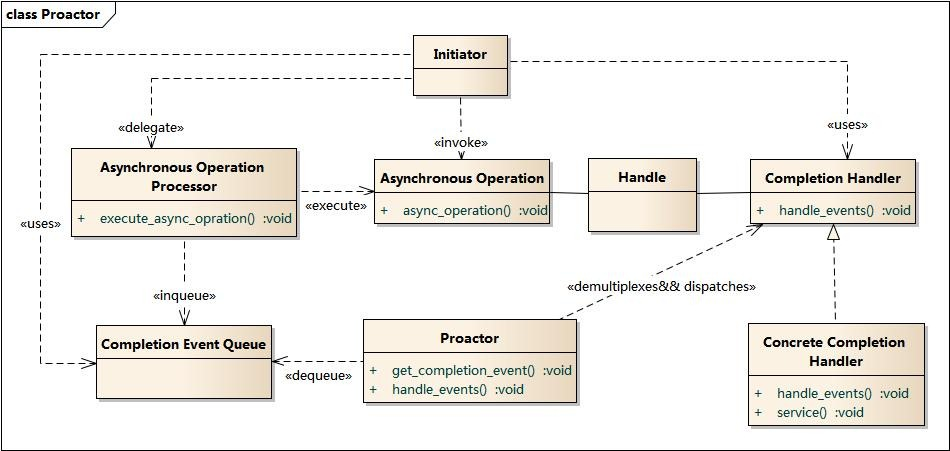
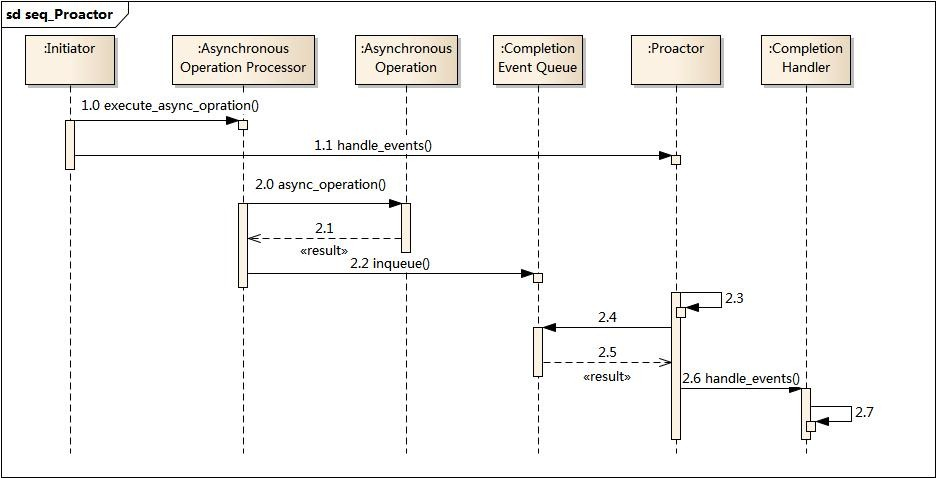
Proactor模式结构
- Handle 句柄;用来标识socket连接或是打开文件;
- Asynchronous Operation Processor:异步操作处理器;负责执行异步操作,一般由操作系统内核实现;
- Asynchronous Operation:异步操作
- Completion Event Queue:完成事件队列;异步操作完成的结果放到队列中等待后续使用
- Proactor:主动器;为应用程序进程提供事件循环;从完成事件队列中取出异步操作的结果,分发调用相应的后续处理逻辑;
- Completion Handler:完成事件接口;一般是由回调函数组成的接口;
- Concrete Completion Handler:完成事件处理逻辑;实现接口定义特定的应用处理逻辑;
Proactor时序图
- 应用程序启动,调用异步操作处理器提供的异步操作接口函数,调用之后应用程序和异步操作处理就独立运行;应用程序可以调用新的异步操作,而其它操作可以并发进行;
- 应用程序启动Proactor主动器,进行无限的事件循环,等待完成事件到来;
- 异步操作处理器执行异步操作,完成后将结果放入到完成事件队列;
- 主动器从完成事件队列中取出结果,分发到相应的完成事件回调函数处理逻辑中;
和Reactor差别
主动和被动
以主动写为例:
Reactor将handle放到select(),等待可写就绪,然后调用write()写入数据;写完处理后续逻辑;
Proactor调用aoi_write后立刻返回,由内核负责写操作,写完后调用相应的回调函数处理后续逻辑;
可以看出,Reactor被动的等待指示事件的到来并做出反应;它有一个等待的过程,做什么都要先放入到监听事件集合中等待handler可用时再进行操作;
Proactor直接调用异步读写操作,调用完后立刻返回;
实现
Reactor实现了一个被动的事件分离和分发模型,服务等待请求事件的到来,再通过不受间断的同步处理事件,从而做出反应;
Proactor实现了一个主动的事件分离和分发模型;这种设计允许多个任务并发的执行,从而提高吞吐量;并可执行耗时长的任务(各个任务间互不影响)
5种IO模型比较

IO模型使用的例子
Redis(6.0之前) => 单线程Reactor
Redis6.0之前都是单线程,Redis6.0以及之后的版本引入多线程
这里单线程指的是网络请求模块使用一个线程来处理,即一个线程处理所有网络请求,其他模块仍用了多个线程,也就是单线程Reactor模式,为什么之前都是单线程官方给出的解释是:
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
意思CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis 的话,如果不考虑 RDB/AOF 等持久化方案,Redis 是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis 真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis 选择了单线程的 I/O 多路复用来实现它的核心网络模型。
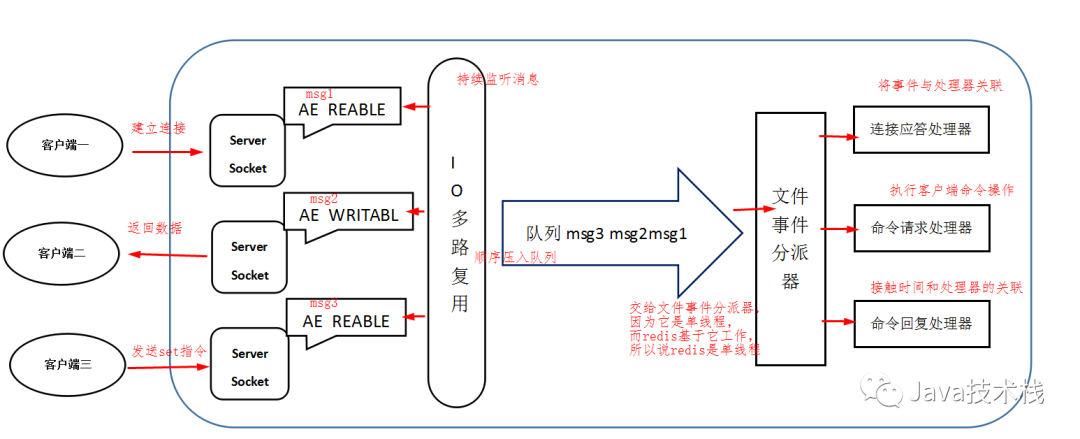
client: 客户端对象
- 客户端通过 socket 与服务端建立网络通道然后发送请求命令,服务端执行请求的命令并回复。Redis 使用结构体 client 存储客户端的所有相关信息,包括但不限于封装的套接字连接 – *conn,当前选择的读入缓冲区 – querybuf,写出缓冲区 – buf,写出数据链表 – reply等。
- aeApiPoll:I/O 多路复用 API,是基于 epoll_wait/select/kevent 等系统调用的封装,监听等待读写事件触发,然后处理,它是事件循环(Event Loop)中的核心函数,是事件驱动得以运行的基础。
- acceptTcpHandler:连接应答处理器,底层使用系统调用 accept 接受来自客户端的新连接,并为新连接注册绑定命令读取处理器,以备后续处理新的客户端 TCP 连接
- readQueryFromClient:命令读取处理器,解析并执行客户端的请求命令。
- beforeSleep:事件循环中进入 aeApiPoll 等待事件到来之前会执行的函数,其中包含一些日常的任务,比如把 client->buf 或者 client->reply (后面会解释为什么这里需要两个缓冲区)中的响应写回到客户端,持久化 AOF 缓冲区的数据到磁盘等,相对应的还有一个 afterSleep 函数,在 aeApiPoll 之后执行。
- sendReplyToClient:命令回复处理器,当一次事件循环之后写出缓冲区中还有数据残留,则这个处理器会被注册绑定到相应的连接上,等连接触发写就绪事件时,它会将写出缓冲区剩余的数据回写到客户端。
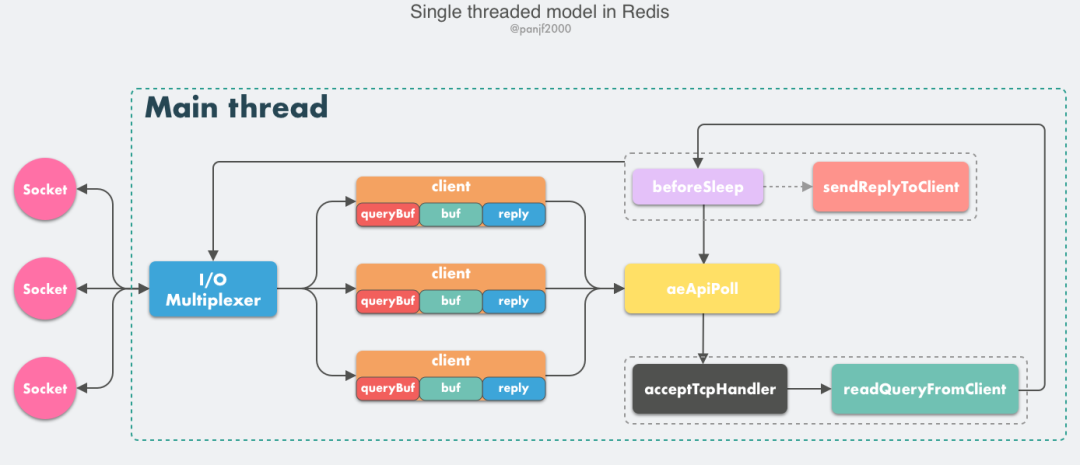
Nginx => master-worker多进程模型
master进程先建好需要监听的socket后,再fork出多个worker进程,这样每个worker进程都可以去接收这个socket。
当一个client连接到来时,所有的worker进程都会收到通知,但只有一个可以accept成功。
- 这里Nginx提供了一个共享锁accept_mutex,虽然所有的worker都会收到通知,但只有一个进程抢到锁,其它失败,成功的worker进程接收请求。
- 当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接。
当运行过程中,如果worker进程出现异常,master会对worker进行重启。重启时会先启动新的worker进程,然后向老的worker发送信号。新的worker启动后,就开始接收新的请求;而老的worker在收到信号后不再接收请求,将当前进程中所有未处理完的请求处理完成后,再退出。
nginx是基于事件模型,适合于IO密集型任务,比如反向代理,IO模型采用epoll实现
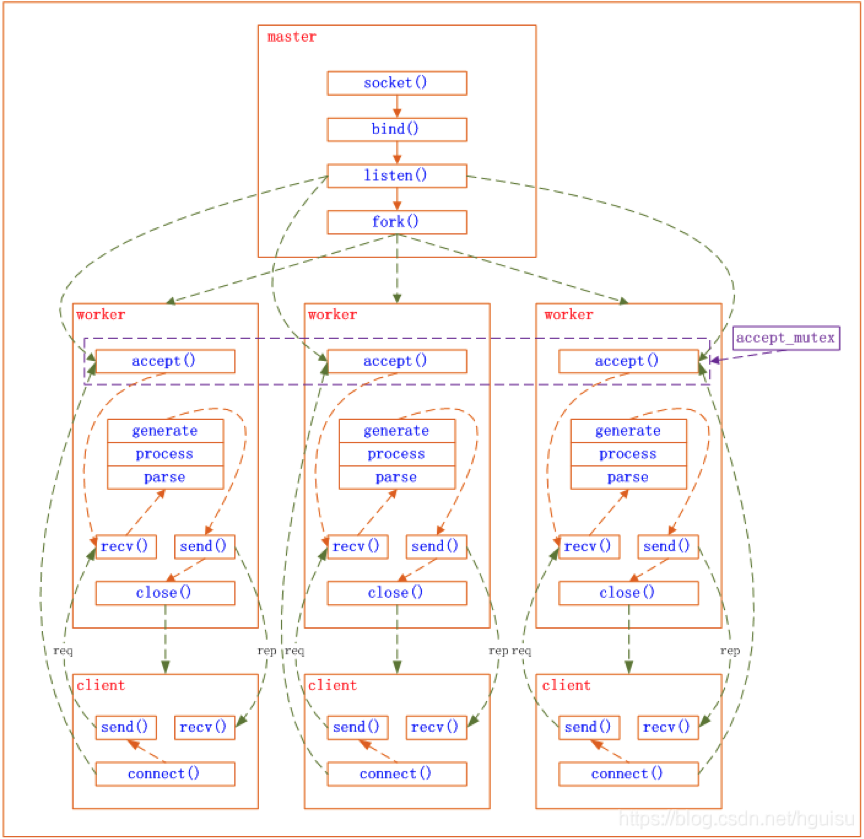
Mysql => 一个连接一个线程或线程池
在 MySQL 5.6出现以前,MySQL 处理连接的方式是
One-Connection-Per-Thread,即对于每一个数据库连接,MySQL-Server都会创建一个独立的线程服务,请求结束后,销毁线程。- 这种方式在高并发情况下,会导致线程的频繁创建和释放。
对于
One-Thread-Per-Connection方式,一个线程对应一个连接,Thread-Pool实现方式中,线程处理的最小单位是statement(语句),一个线程可以处理多个连接的请求。这样,在保证充分利用硬件资源情况下(合理设置线程池大小),可以避免瞬间连接数暴增导致的服务器抖动。MySQL-Server 同时支持3种连接管理方式,包括
No-Threads,One-Thread-Per-Connection和Pool-Threads。- No-Threads 表示处理连接使用主线程处理,不额外创建线程,这种方式主要用于调试;
- One-Thread-Per-Connection 是线程池出现以前最常用的方式,为每一个连接创建一个线程服务;
- Pool-Threads 则是本文所讨论的线程池方式。Mysql-Server通过一组函数指针来同时支持3种连接管理方式,对于特定的方式,将函数指针设置成特定的回调函数,连接管理方式通过thread_handling参数控制,代码如下:
123456if (thread_handling <= SCHEDULER_ONE_THREAD_PER_CONNECTION)one_thread_per_connection_scheduler(thread_scheduler,&max_connections, &connection_count);else if (thread_handling == SCHEDULER_NO_THREADS)one_thread_scheduler(thread_scheduler);elsepool_of_threads_scheduler(thread_scheduler, &max_connections,&connection_count);通过poll监听mysql端口的连接请求 收到连接后,调用accept接口,创建通信socket
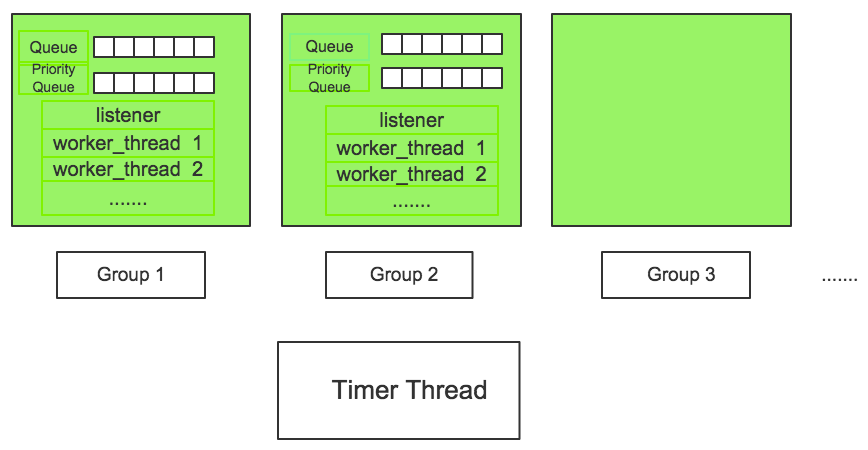
mysql线程池实现框架
- 每一个绿色的方框代表一个group,group数目由thread_pool_size参数决定。
- 每个group包含一个优先队列和普通队列,包含一个listener线程和若干个工作线程,listener线程和worker线程可以动态转换,worker线程数目由工作负载决定,同时受到thread_pool_oversubscribe设置影响。
- 此外,整个线程池有一个timer线程监控group,防止group“停滞”。
连接池与线程池
- 连接池通常实现在 Client 端,是指应用(客户端)创建预先创建一定的连接,利用这些连接服务于客户端所有的DB请求。如果某一个时刻,空闲的连接数小于DB的请求数,则需要将请求排队,等待空闲连接处理。通过连接池可以复用连接,避免连接的频繁创建和释放,从而减少请求的平均响应时间,并且在请求繁忙时,通过请求排队,可以缓冲应用对DB的冲击。
- 线程池实现在server端,通过创建一定数量的线程服务DB请求,相对于
one-conection-per-thread的一个线程服务一个连接的方式,线程池服务的最小单位是语句,即一个线程可以对应多个活跃的连接。通过线程池,可以将 server 端的服务线程数控制在一定的范围,减少了系统资源的竞争和线程上下文切换带来的消耗,同时也避免出现高连接数导致的高并发问题。 - 如下图:每个web-server端维护了3个连接的连接池,对于连接池的每个连接实际不是独占db-server的一个worker,而是可能与其他连接共享。这里假设db-server只有3个group,每个group只有一个worker,每个worker处理了2个连接的请求。
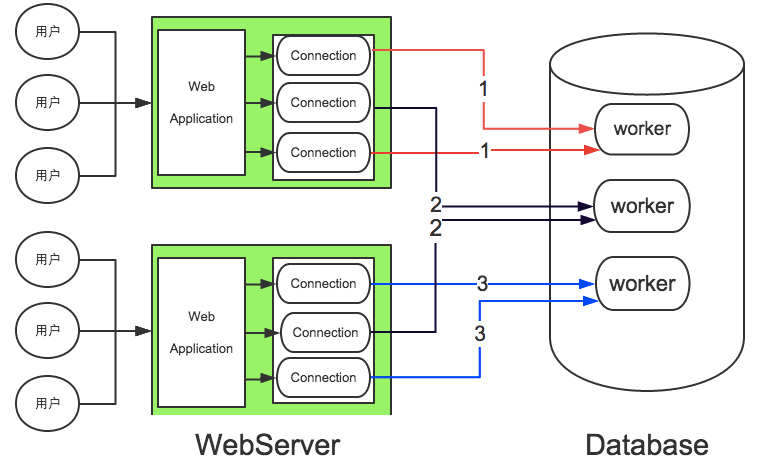
mysql为什么使用连接池而不使用IO多路复用,网上有一些解答:
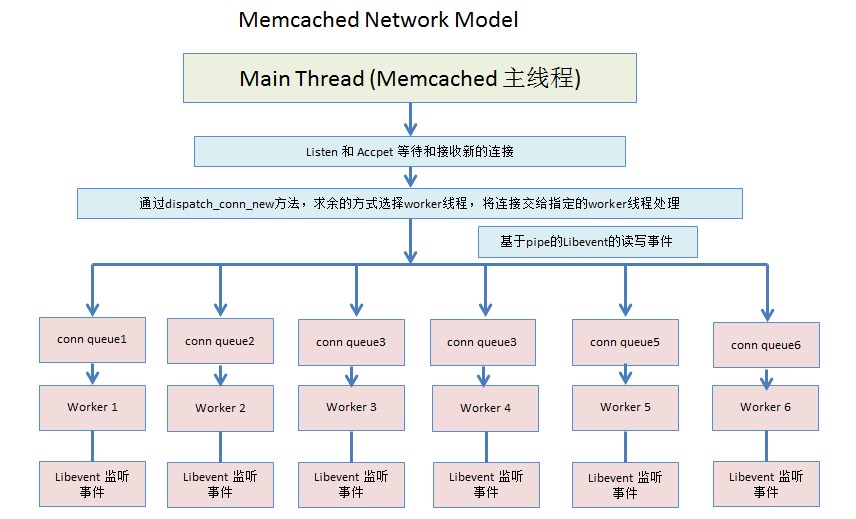
Memcache =》 单listener+固定worker线程
- memcached不同于Redis的单进程单线程,是采用多线程的工作方式。
- 有一个主线程,同时维护了一个线程池(工作线程)。worker thread工作线程和main thread主线程之间主要通过pipe来进行通信。
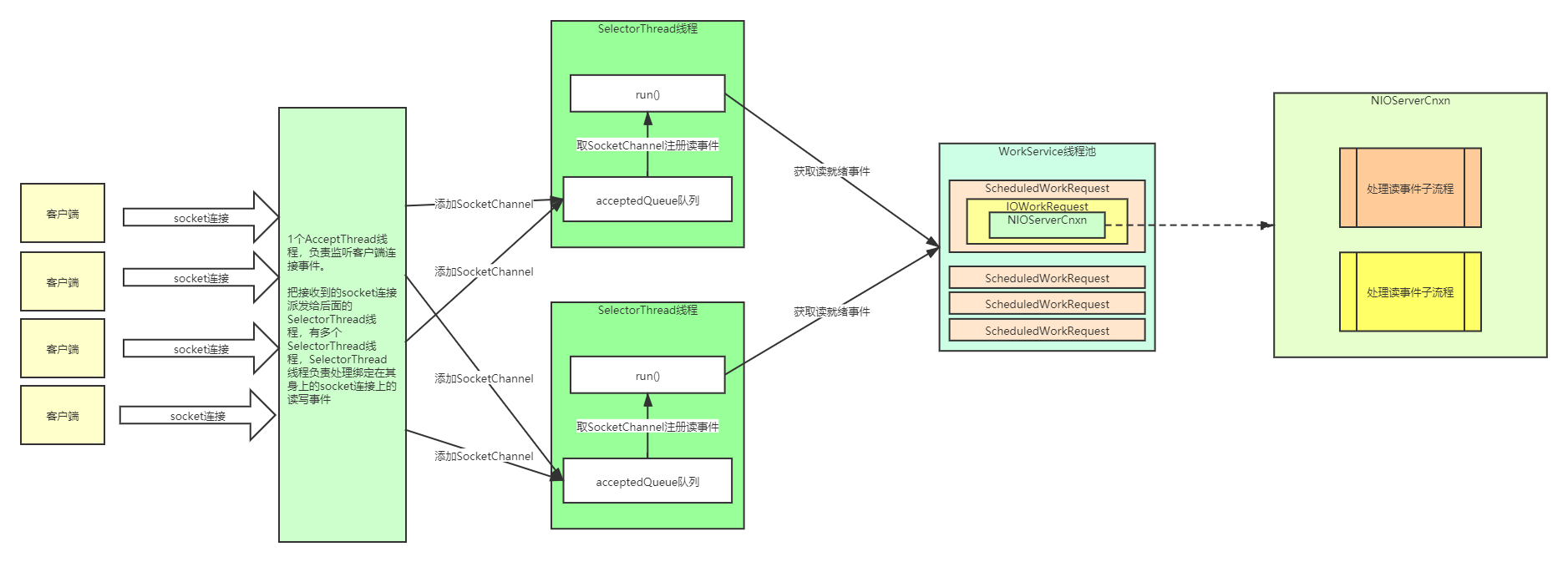
Zookeeper
- 在服务端有一个线程(AccpectThread),该线程负责处理客户端建立连接建立,并在连接建立后将该连接放入到一个队列(AcceptedQueue)。
- 紧接着线程(SelectThread)负责从队列取出连接进行处理,只要IO操作准备就绪(可读、可写),该连接会被扔到工作线程中进行处理。
- 类似主从Reactor
Reference
- https://mp.weixin.qq.com/s/O9E6ceTWVLGSarbbHR0qqA
- https://mp.weixin.qq.com/s/EDzFOo3gcivOe_RgipkTkQ
- http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
- https://mp.weixin.qq.com/s/-d8E56sBa7X-6_20vQJ45A
- https://blog.csdn.net/stromcruise/article/details/117606997
- https://mp.weixin.qq.com/s/mKJrOMo8c1IYOZSvY4Rp1A


- 本文链接: http://lawlite.me/2022/08/27/高并发网络线程模型/
-
版权声明:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议
 。转载请注明出处!
。转载请注明出处!